
Exploring AI Accessibility and Independence. Spring 2025 Workshop Series
Large language models are revolutionizing how we interact with technology, but access to these powerful tools has been largely controlled by major corporations through cloud services. What if you could run these sophisticated AI models directly on your own hardware, maintaining privacy, avoiding subscription fees, and gaining complete control over their operation? Open source LLMs make this possible, and they're becoming increasingly accessible to everyday users.
In this workshop, we explore what open source means in the context of AI, how local LLMs differ from cloud-based alternatives, and provide hands-on experience with setting up and using LM Studio to run these models on personal computers. We also examine essential concepts like model sizes, context windows, and performance optimization techniques including quantization – all aimed at empowering you to use advanced AI while maintaining your digital independence.
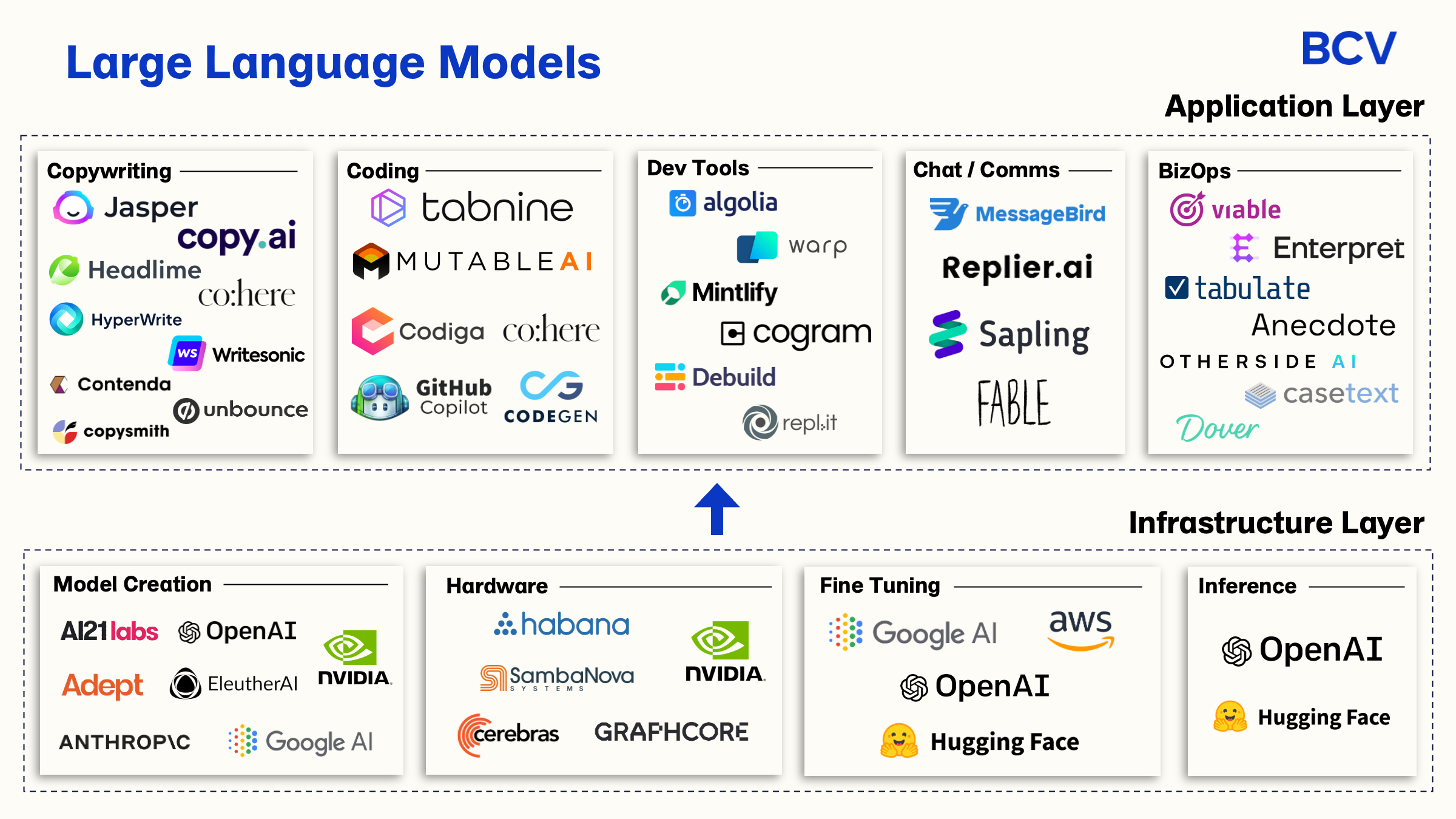
Open source refers to software whose source code is made freely available for anyone to use, modify, and distribute. Different levels of "open-sourcedness" exist, with some models being fully open while others may have limitations on commercial use or other restrictions. This openness stands in contrast to proprietary systems where code and weights are closely guarded secrets.

Key examples of open source in the AI ecosystem include:
Platforms: Hugging Face, which hosts libraries for natural language processing and numerous AI models
Frameworks: TensorFlow, PyTorch that enable AI development
Models: DeepSeek, Qwen, Llama, and Mistral – powerful language models with publicly available weights

The open source philosophy has been crucial for democratizing AI technology, allowing researchers, developers, and enthusiasts to understand, customize, and improve these systems without corporate gatekeeping.
Large Language Models (LLMs) are very large deep learning models trained on massive text datasets. They use advanced architectures (primarily Transformers) to predict and generate text in a human-like way. Their importance cannot be overstated – these models power popular AI applications like chatbots and content generators, with the flexibility to perform many language tasks including answering questions, summarizing documents, translating text, and writing code.
When it comes to actually using these models, users face a choice between cloud-based and local deployment:

Cloud-Based LLMs: These run on remote servers, accessed through APIs from providers like OpenAI. While convenient, they require internet connectivity, send your data to third-party servers, and often come with significant subscription costs. They can also face overload issues during peak demand, as seen when models like DeepSeek initially launched.
Local LLMs: These run directly on your own machine. All processing happens offline on your hardware, so your data never leaves your computer. While they require sufficient computing resources (CPU/RAM and ideally GPU), they offer complete privacy, no subscription fees, and the ability to work offline.
LM Studio: https://lmstudio.ai/
To provide practical experience with local LLMs, participants engaged in a hands-on session using LM Studio, a user-friendly application for running these models on personal computers.
The activity began with selecting appropriate models – starting with smaller 1.5B parameter models to ensure everyone could run them regardless of hardware limitations. After loading the models, participants tested basic prompting with simple questions and greetings, confirming their setups were working correctly and getting a feel for response speeds and styles.
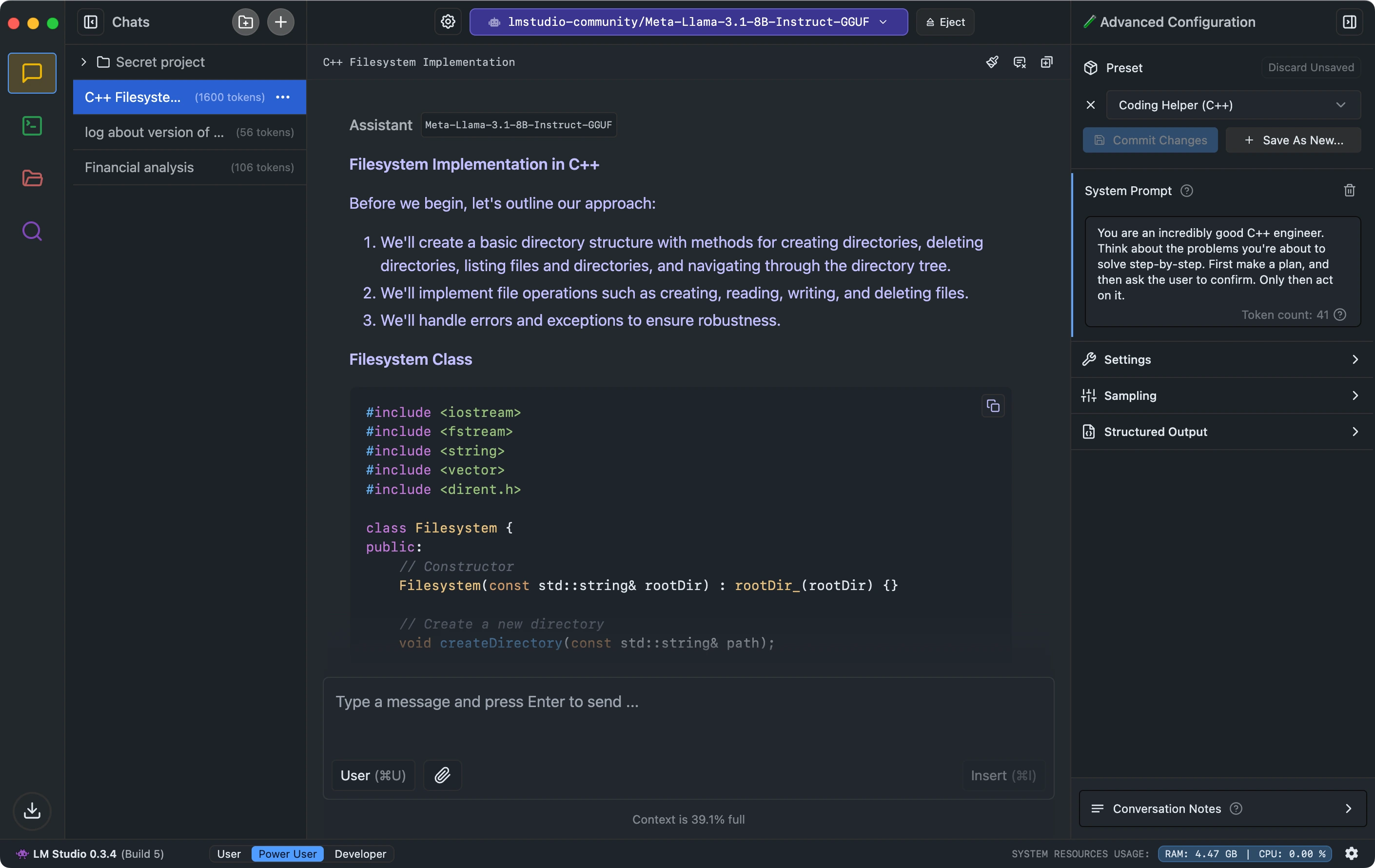
More adventurous participants explored prompt engineering techniques, comparing responses between differently phrased prompts. For example, asking the model to "List three fun facts about AI" versus "You are an AI expert. Explain three fun facts about artificial intelligence in simple terms." These exercises highlighted how, even with smaller local models, effective prompting can significantly improve outputs.
An advantage of using local models became apparent during the exercises – without the limitations of cloud-based systems, participants could freely experiment with system-level prompts and observe how the model's behavior changed. This flexibility is typically restricted in commercial systems due to guardrails that prevent certain types of interactions.
One of the most critical aspects of running local LLMs is understanding how to select appropriate models and configure them effectively. Participants learned about several key concepts:
Model size, measured by the number of parameters, significantly impacts both performance and hardware requirements:
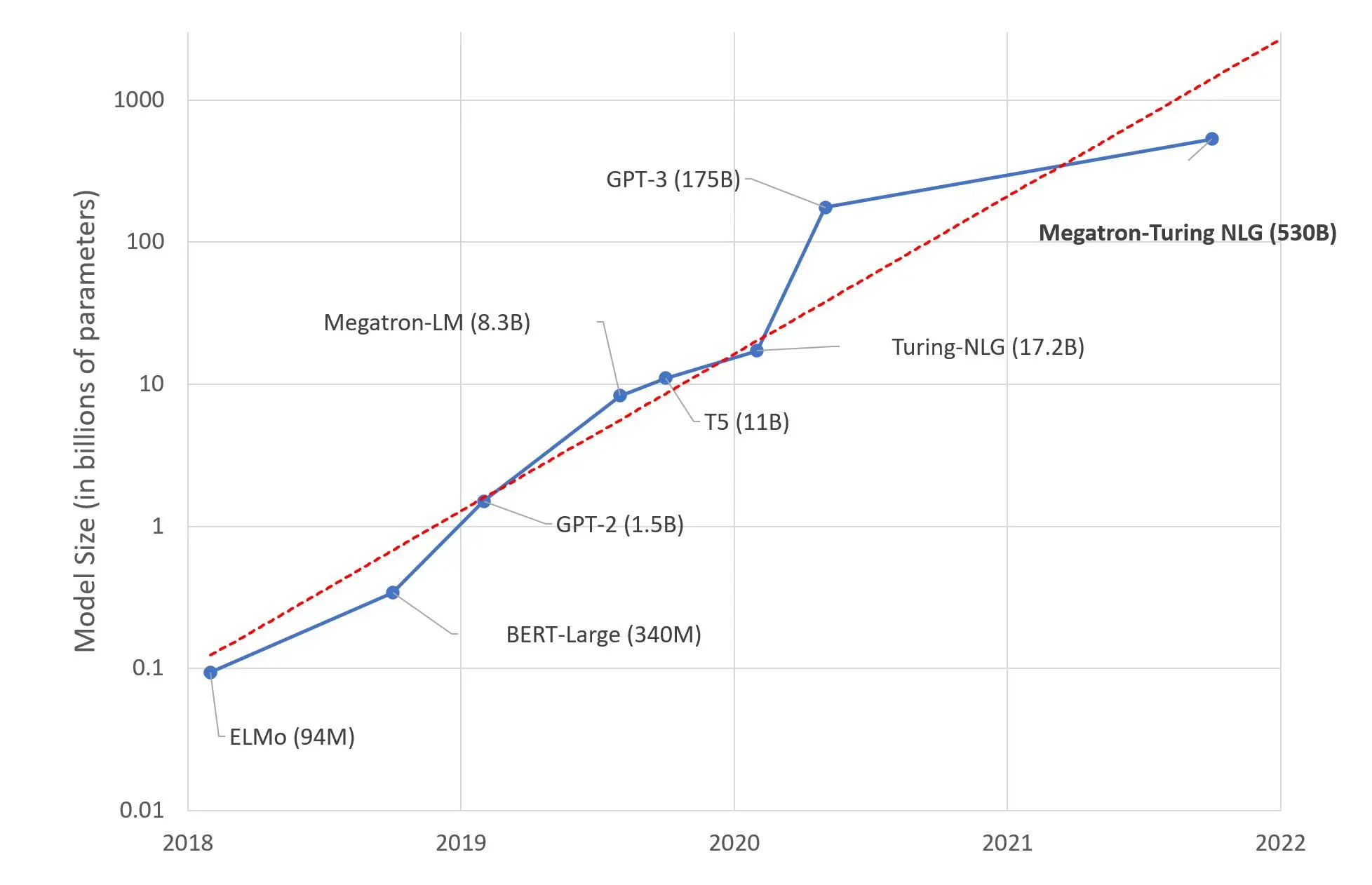
Smaller models (1.5B-7B parameters): Run faster and require less memory, but may produce less fluent or accurate responses
Medium models (13B parameters): Offer a good balance between quality and resource requirements
Larger models (30B-70B+ parameters): Generate higher-quality outputs but demand substantial computing power
The workshop explained how model size affects computational complexity, with larger models requiring exponentially more resources to run efficiently.
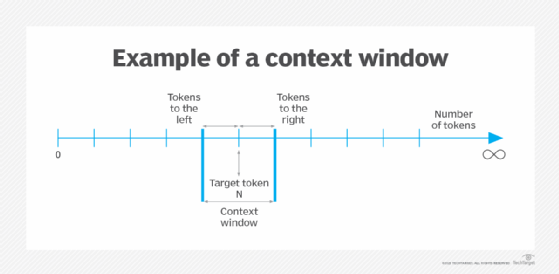
The context window represents how much text the model can "remember" during a conversation:
Measured in tokens (roughly 0.75 words per token in English)
Smaller models might have 2048-token context windows
Newer models may offer 4K, 8K, 16K, or even longer contexts
Larger context windows allow for longer documents or extended dialogues without the model forgetting earlier details
Participants learned that the context window is often considered the "kryptonite of transformers," as extending it dramatically increases computational requirements.
The workshop covered essential settings that control model behavior:
Temperature: Controls randomness in responses (lower values = more focused/deterministic; higher = more creative but potentially less coherent)
Top-K/Top-P Sampling: Limits token selection to the most probable options, affecting creativity versus consistency
Repeat Penalty: Discourages repetitive outputs, with values above 1.0 reducing repetition
Min-P Sampling: Sets a minimum probability threshold for token selection, improving coherence
Speculative Decoding: Uses a smaller "draft model" to speed up generation
Participants experimented with these settings to observe their effects on model outputs, learning that temperature settings of 0 aren't always optimal, particularly for creative tasks.
For many users, hardware limitations present a significant barrier to running larger, more capable LLMs. The workshop addressed this challenge by explaining quantization – a technique that makes large models more efficient by using lower-precision numbers for parameters.
How Quantization Works:
Instead of using 32-bit or 16-bit floating-point numbers for weights, quantization reduces them to 8-bit, 4-bit, or even smaller integer representations
This dramatically reduces memory requirements – a 7B parameter model that might need 30GB at full precision can run in 7-8GB after quantization
The tradeoff is a small reduction in accuracy that's often barely noticeable in practice


Types of Quantization:
Q4_K_M: 4-bit quantization with medium accuracy/performance tradeoff
Q8_0: 8-bit quantization with higher accuracy but larger size
Q6_K: 6-bit quantization offering a balance of quality and efficiency
This technique has democratized access to powerful LLMs, making it possible to run sophisticated AI on consumer-grade hardware like laptops and desktops without specialized equipment.
As the workshop concluded, participants reflected on several essential insights about local LLMs:
Empowerment Through Local Control: Running LLMs locally provides privacy, independence from cloud services, and the freedom to experiment without restrictions.
Resource-Aware Model Selection: Understanding the relationship between model sizes, hardware requirements, and performance helps users make informed choices about which models to use.
Optimization Techniques: Quantization and parameter tuning can significantly improve the experience of running LLMs locally, even on modest hardware.
Accessibility of AI: Open source models are making powerful AI accessible to everyone, not just those with enterprise resources or significant budgets.
The hands-on experience provided participants with the practical knowledge needed to continue exploring local LLMs on their own, with recommendations to start with smaller models and gradually explore larger ones as they become more comfortable with the technology.
